JPA란?
- 자바 표준 ORM(Object Relational Mapping)기술
- MyBatis, iBatis는 ORM이 아니고 SQL Mapper임
왜 JPA를 쓰나?
- 관계형 데이터베이스와 객체지향 프로그래밍 언어의 패러다임이 서로 다른데, 객체를 데이터베이스에 저장하려고 하니 여러 문제가 발생 -> 패러다임 불일치
- 서로 지향하는 바가 다른 2개 영역(객체지향 프로그래밍 언어와 관계형 데이터베이스)을 중간에서 패러다임 일치를 시켜주기 위한 기술
실무에서 JPA
- 실무에서 JPA를 사용하지 못하는 가장 큰 이유는 높은 러닝 커브
- 즉, JPA를 잘 쓰려면 객체지향 프로그래밍과 데이터베이스를 둘 다 이해해야 하기 때문
프로젝트에 Spring Data Jpa 적용하기
build.gradle에 의존성들을 등록
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
implementation 'com.h2database:h2'spring-boot-starter-data-jpa
- 스프링 부트용 Spring Data Jpa 추상화 라이브러리
- 스프링 부트 버전에 맞춰 자동으로 JPA관련 라이브러리들의 버전을 관리 해줍니다.
h2
- 인메모리 관계형 데이터베이스
- 별도의 설치가 필요 없이 프로젝트 의존성만으로 관리 가능
- 메모리에서 실행되기 때문에 애플리케이션을 재시작 할 때마다 초기화된다는 점을 이용하여 테스트 용도로 많이 사용
왜? Spring Data JPA를 쓰나?
- 구현체 교체의 용이성 -- 다른 구현체로 쉽게 교체 가능
- 저장소 교체의 용이성 -- 관계형 데이터베이스 외에 다른 저장소로 쉽게 교체 가능
domain이란?
- 게시글, 댓글, 회원, 정산, 결제 등 소프트웨어에 대한 요구사항 혹은 문제 영역
- .xml에서 쿼리를 담고, 클래스는 오로지 쿼리의 결과만 담던 일들이 모두 도메인 클래스에서 해결
domain 패키지에 posts 패키지에 Posts 클래스 생성

Posts 클래스
package com.danny.makewebalone.web.domain.posts;
import lombok.Builder;
import lombok.Getter;
import lombok.NoArgsConstructor;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
@Getter
@NoArgsConstructor
@Entity
public class Posts {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(length = 500, nullable = false)
private String title;
@Column(columnDefinition = "TEXT", nullable = false)
private String content;
private String author;
@Builder
public Posts(String title, String content, String author) {
this.title = title;
this.content = content;
this.author = author;
}
}@Entity
- 테이블과 링크될 클래스임을 나타냄
- 기본값으로 클래스의 카멜케이스 이름을 언더스코어 네이밍(_)으로 테이블 이름을 매칭
- ex) DannyJeong.java -> danny_jeong table
- Entity 클래스에서는 절대 Setter 메소드를 만들지 말 것
@Id
- 해당 테이블의 PK필드를 나타냄
- 웬만하면 Entity의 PK는 Long 타입의 Auto_increment를 추천
@GeneratedValue
- PK의 생성 규칙을 나타냄
@Column
- 테이블의 컬럼을 나타내며 굳이 선언하지 않더라도 해당 클래스의 필드는 모두 컬럼이 됨
- 그럼에도 사용하는 이유는 기본값 외에 추가로 변경이 필요한 옵션이 있으면 사용
- ex) 문자열의 사이즈를 늘리고 싶을 때 VARCHAR(255) -> 500
@NoArgsConstructor
- 기본 생성자 자동 추가
- public Posts(){}와 같은 효과
@Getter
- 클래스 내 모든 필드의 Getter 메소드를 자동생성
@Builder
- 해당 클래스의 빌더 패턴 클래스를 생성
- 생성자 상단에 선언 시 생성자에 포함된 필드만 빌더에 포함
Builder 패턴이란?
- 인자들이 많아 질 수록 생성자의 숫자 역시 많아지고 매개변수로 필수 인자도 구분해서 생성자를 만들어야 함
- 그렇게 되면 코드가 많아지고 인자가 추가되는 일이 발생한다면 코드를 수정하기 어려움
- 또한 코드 가독성도 떨어짐
하지만 Builder 패턴을 이용한다면?
Posts.class
@Builder
public Posts(String title, String content, String author) {
this.title = title;
this.content = content;
this.author = author;
}
Controller
postsRepository.save(Posts.builder()
.title("SeongJin")
.content("Don't give up")
.author("danny@gmail.com")
.build());- 깔끔.
Class에 Setter가 없으면 어떻게 DB에 insert하나?
- 기본적인 구조는 생성자를 통해 최종값을 채운 후 DB에 삽입하는 것
- 값 변경이 필요한 경우 해당 이벤트에 맞는 public 메소드를 호출하여 변경하는 것을 전제로 함
- 본 교재에서는 생성자 대신에 @Builder 어노테이션을 사용
Posts클래스로 DB를 접근하게 해줄 JpaRepository인 PostsRepository생성
package com.danny.makewebalone.web.domain.posts;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.Query;
import java.util.List;
public interface PostsRepository extends JpaRepository<Posts, Long> {
}- MyBatis 등에서 Dao라고 불리는 DB Layer 접근자
- JPA에선 Repository라고 부르며 인터페이스로 생성
- 단순히 인터페이스를 생성 후, JpaRepository<Entity 클래스, PK 타입>를 상속하면 기본적인 CRUD 메소드가 자동으로 생성
- Entity 클래스와 기본 Repository는 도메인 패키지에 함께 위치할 것
Spring Data JPA 테스트 코드 작성하기
package com.danny.makewebalone.web.domain.posts;
import org.junit.After;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.time.LocalDateTime;
import java.util.List;
import static org.assertj.core.api.Assertions.assertThat;
@RunWith(SpringRunner.class)
@SpringBootTest
public class PostsRepositoryTest {
@Autowired
PostsRepository postsRepository;
@After
public void cleanup() {
postsRepository.deleteAll();
}
@Test
public void 게시글저장_불러오기() {
//given
String title = "테스트 게시글";
String content = "테스트 본문";
postsRepository.save(Posts.builder()
.title(title)
.content(content)
.author("danny@gmail.com")
.build());
//when
List<Posts> postsList = postsRepository.findAll();
//then
Posts posts = postsList.get(0);
assertThat(posts.getTitle()).isEqualTo(title);
assertThat(posts.getContent()).isEqualTo(content);
}
}@After
- Junit에서 단위 테스트가 끝날 때마다 수행되는 메소드를 지정
- 보통은 배포 전 전체 테스트를 수행할 때 테스트간 데이터 침범을 막기 위해 사용
- 여러 테스트가 동시에 수행되면 테스트용 데이터베이스인 H2에 데이터가 그대로 남아 있어 다음 테스트 실행 시 테스트가 실패할 수 있음
postsRepository.save
- 테이블 posts에 insert/update 쿼리를 실행
- id 값이 있다면 update, 없다면 insert 쿼리가 실행
postsRepository.findAll
- 테이블 posts에 있는 모든 데이터를 조회해오는 메소드
+ 추가
- 별다른 설정 없이 @SpringBootTest를 사용할 경우 H2 데이터베이스를 자동으로 실행함
- application.properties파일에 spring.jpa_show_sql=true 옵션 추가시에 테스트후 콘솔에서 쿼리 로그 확인 가능
Test 결과
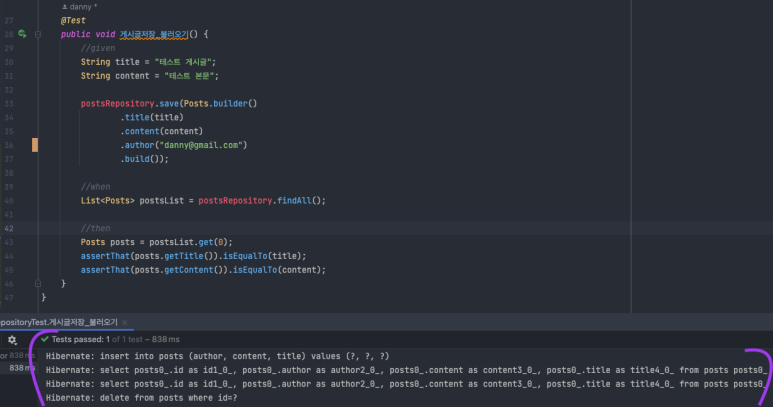
Passed
'스프링 부트와 AWS' 카테고리의 다른 글
| 03장. 스프링 부트에서 JPA로 데이터베이스 다뤄보자03 (0) | 2022.11.14 |
|---|---|
| 03장. 스프링 부트에서 JPA로 데이터베이스 다뤄보자02 (0) | 2022.11.11 |
| 02장. 스프링 부트에서 테스트 코드를 작성하자 (0) | 2022.11.11 |
| 01장. 인텔리제이로 스프링 부트 시작하기 (0) | 2022.11.11 |
| 스프링 부트와 AWS로 혼자 구현하는 웹 서비스 (0) | 2022.11.11 |




댓글